EuroFab Progress Meeting
2024-10-04
Problems with existing datasets - EUBUCCO, etc..

Lots of missing and undocumented processed data
Problems with cadastre data - Germany, Poland, etc..

Wrong and undocumented information - CRS, type, year, rate-limited APIs
Examples

Good coverage, but quality drops some places
Examples

Simplified Overture street network
Urban Fabric Examples

Medieval, Victorian-era and ‘Large, open’ urban fabrics)
Urban Fabric Examples

Modern, Victorian-era and villas
Urban Fabric Examples

First mode iteration coarse hierarchy cut
First iteration results

Baseline
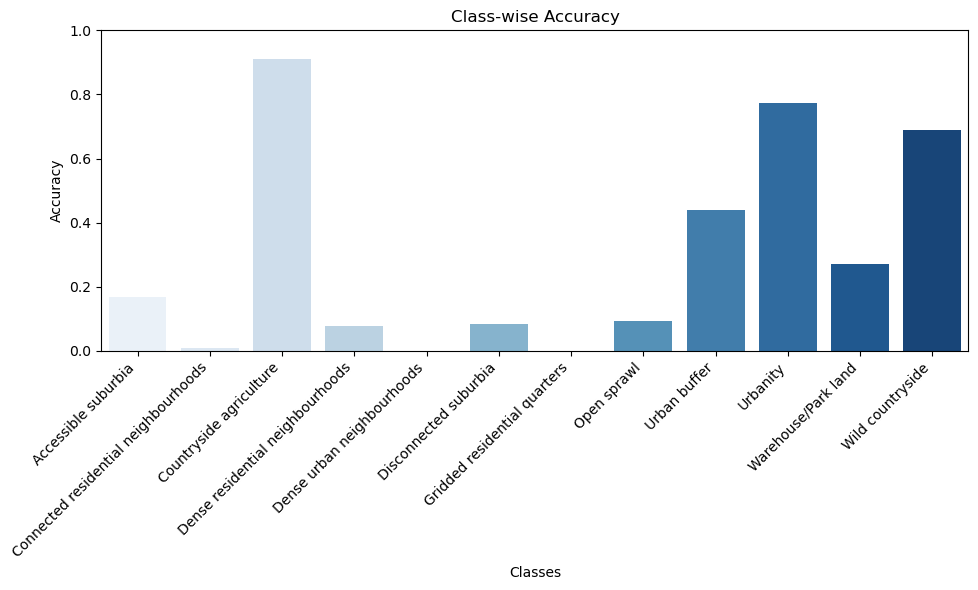
Baseline: Results
WP 202: AI model design

Train/test
80/20% 
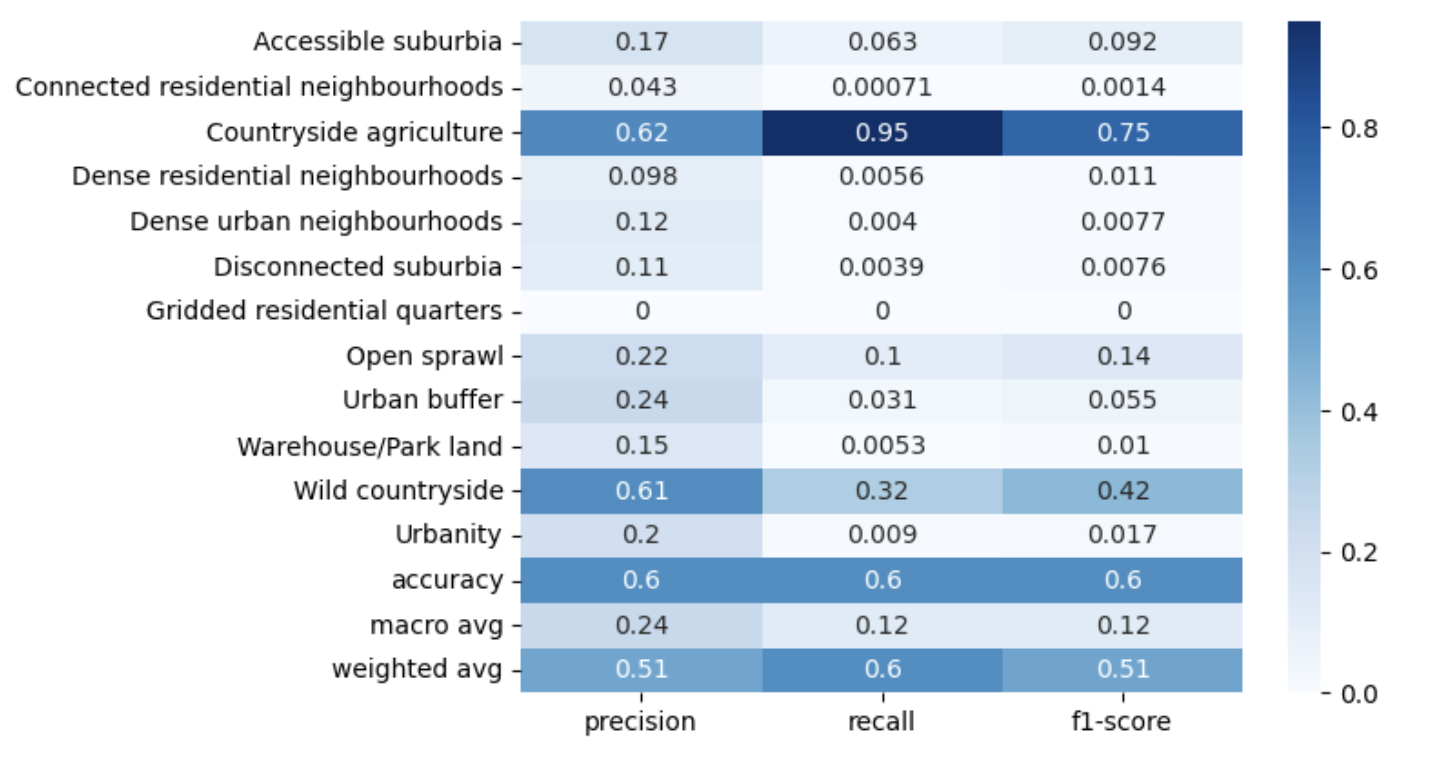
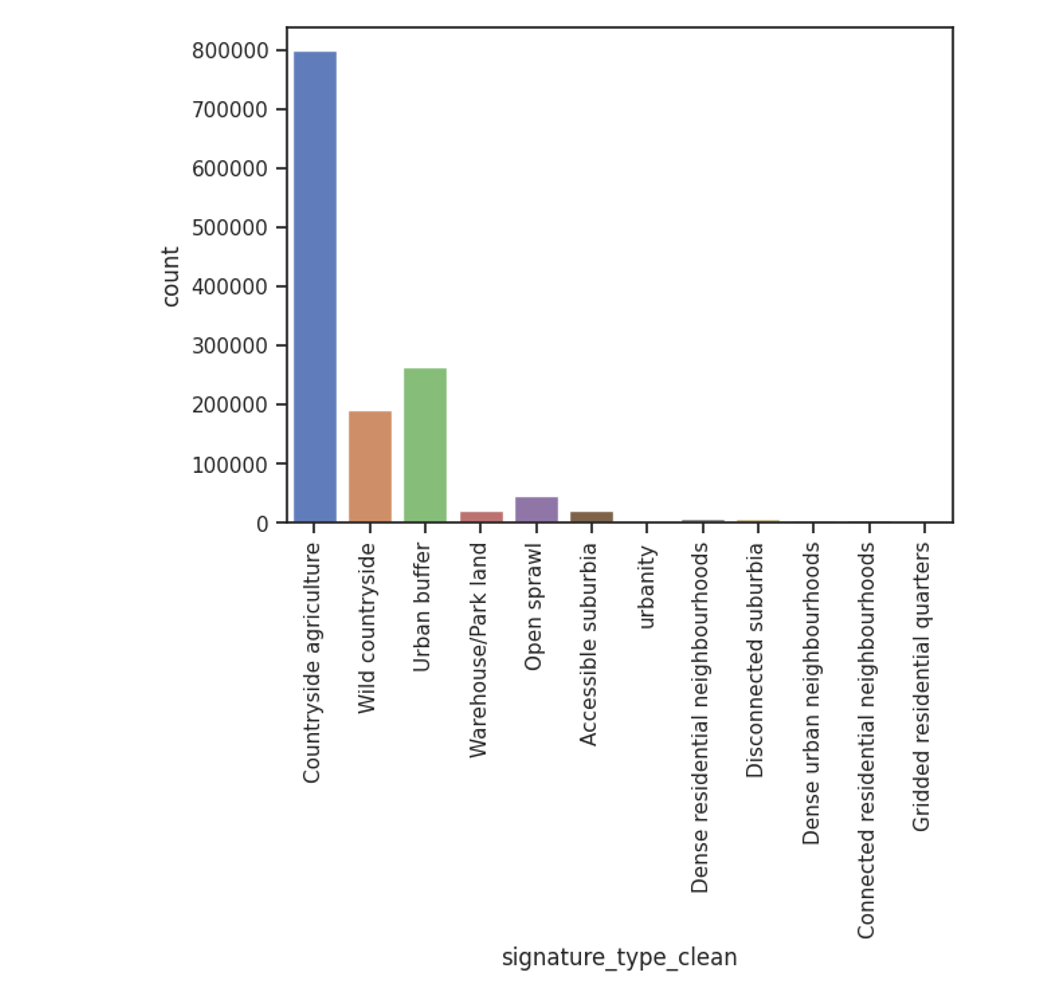
Unbalanced dataset
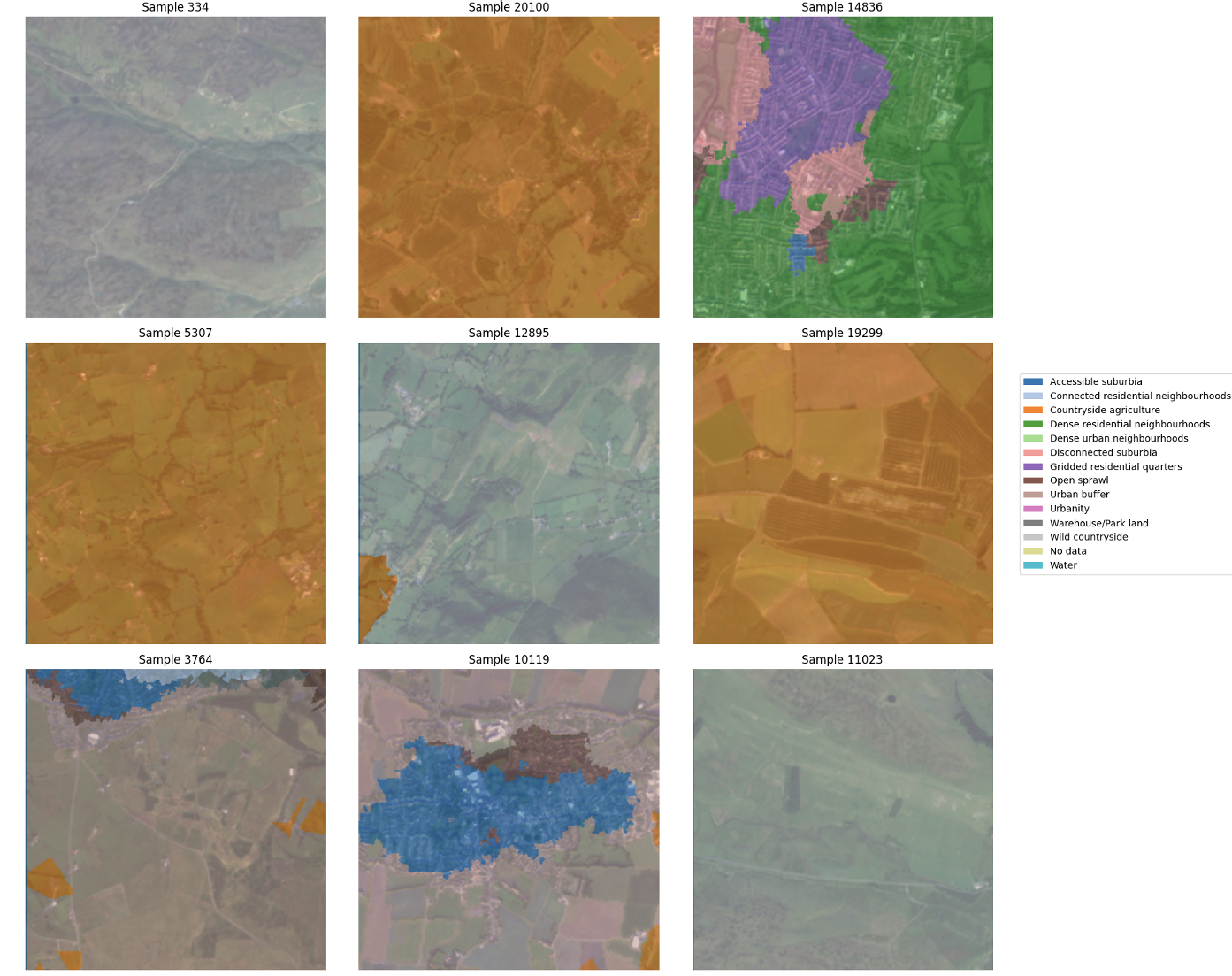
Example
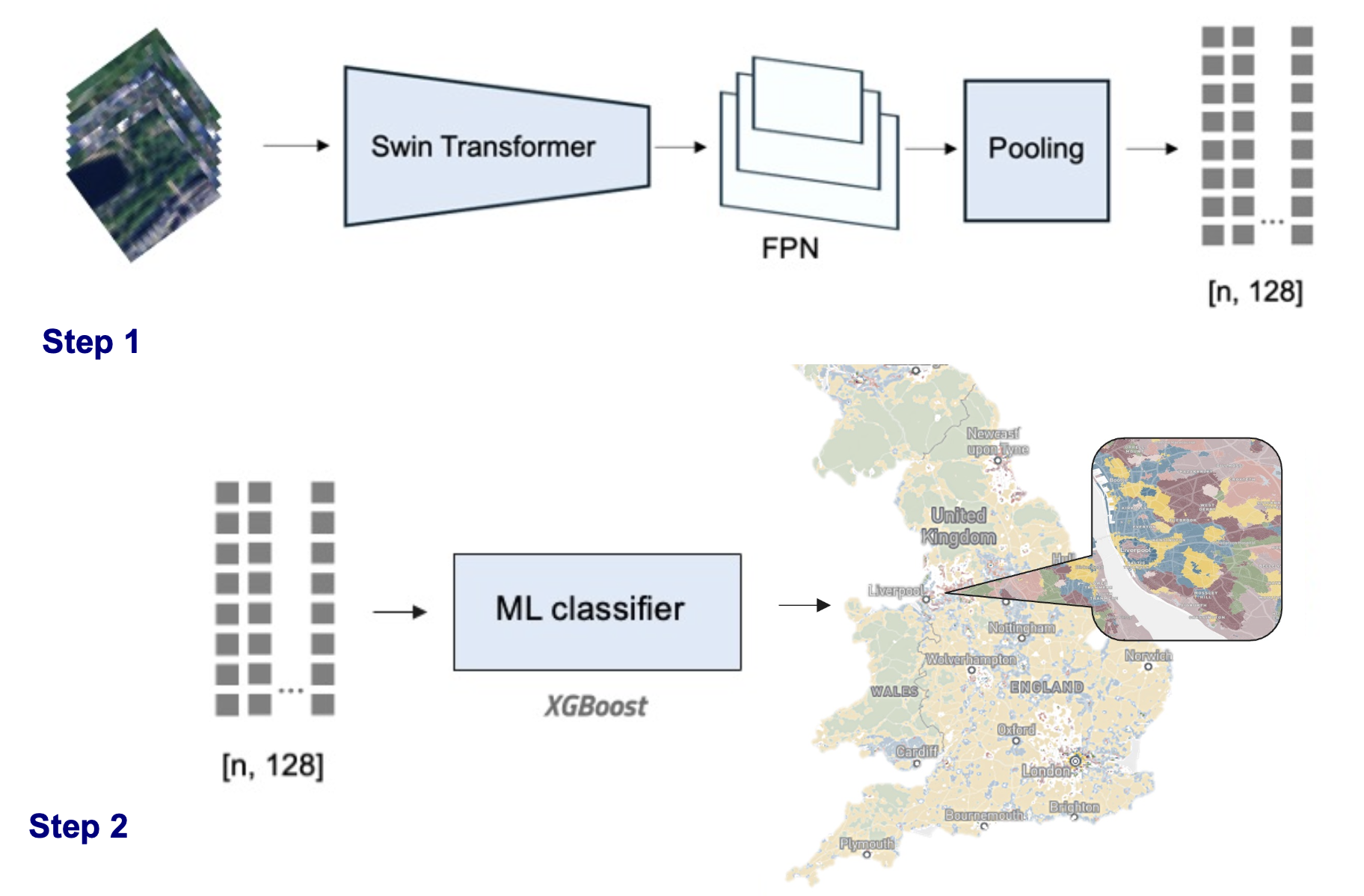
Model design
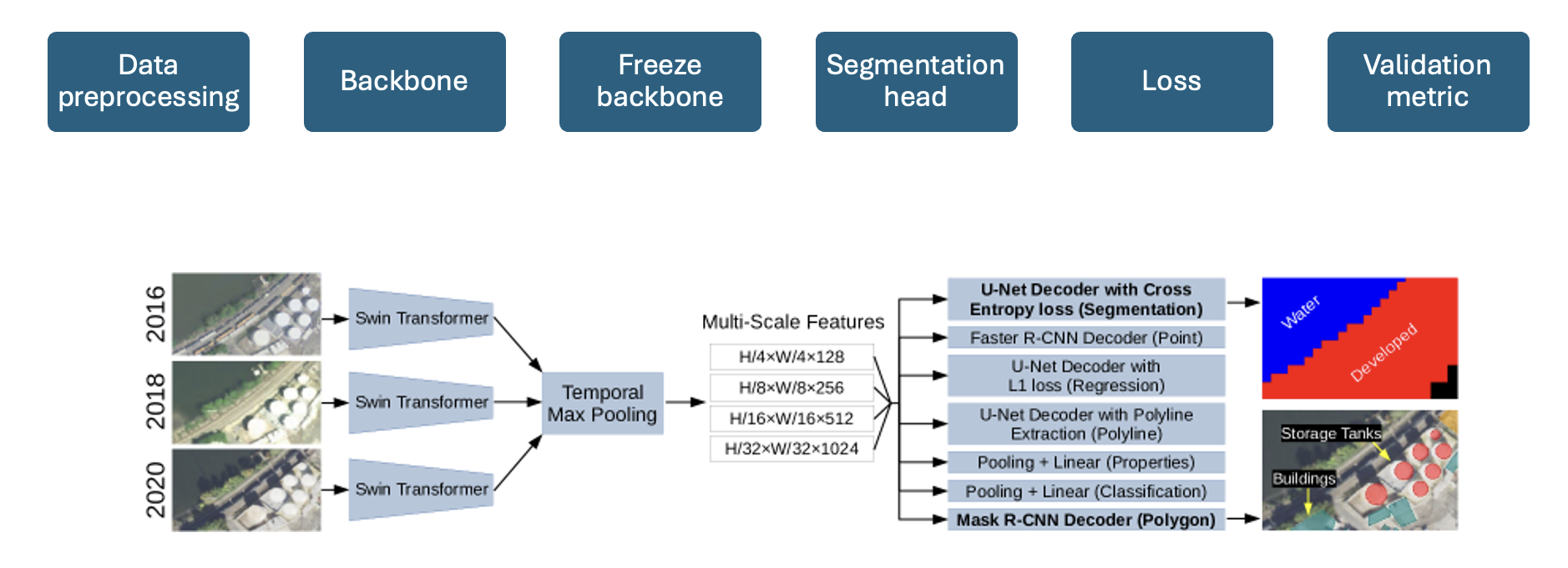
Model design
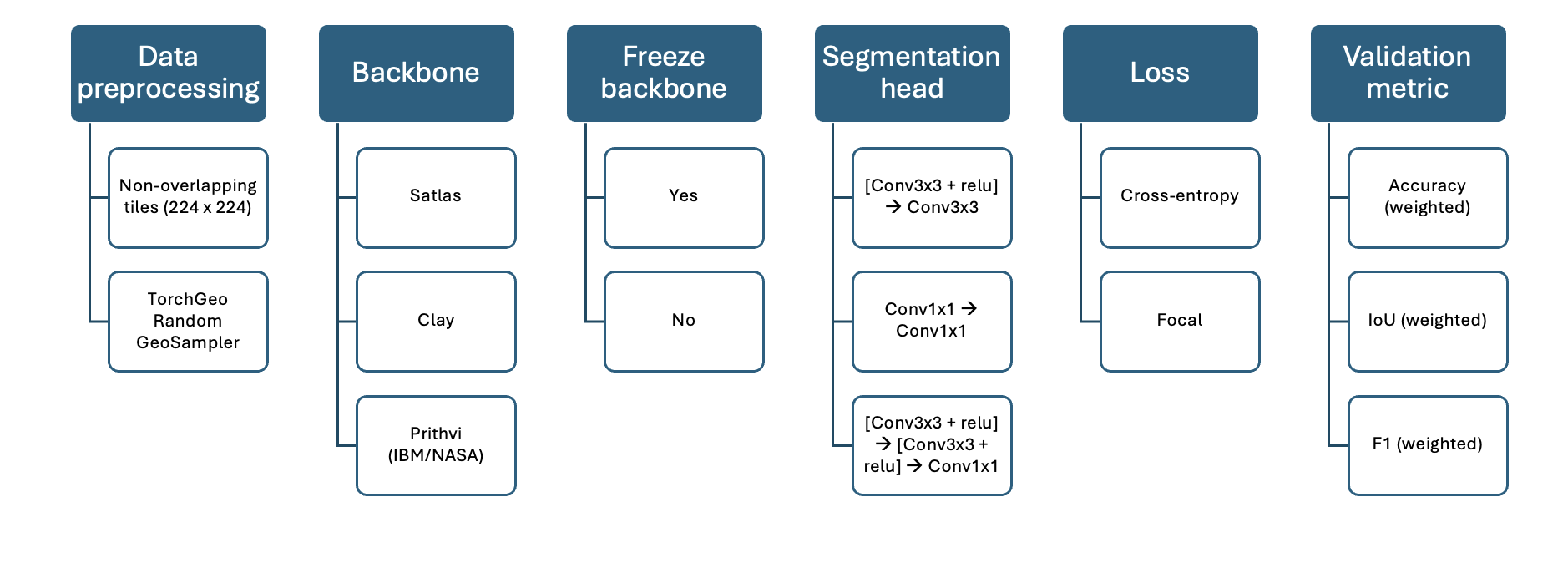
Backbone: foundation models
- Satlas
- Clay
- IBM/NASA (Prithvi)
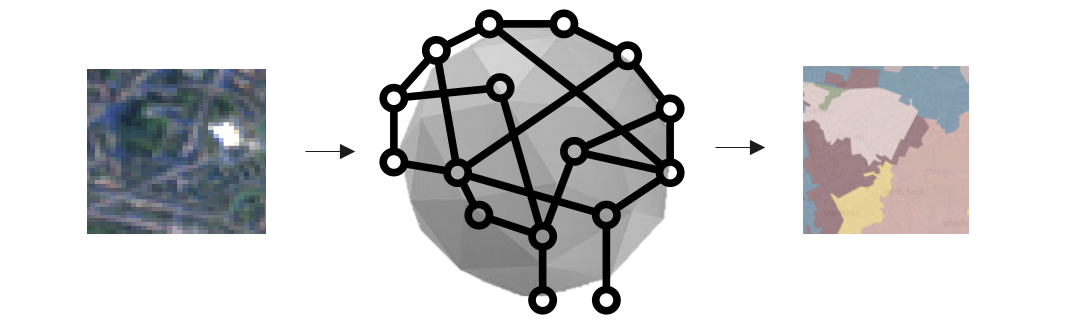
Model A: Satlas
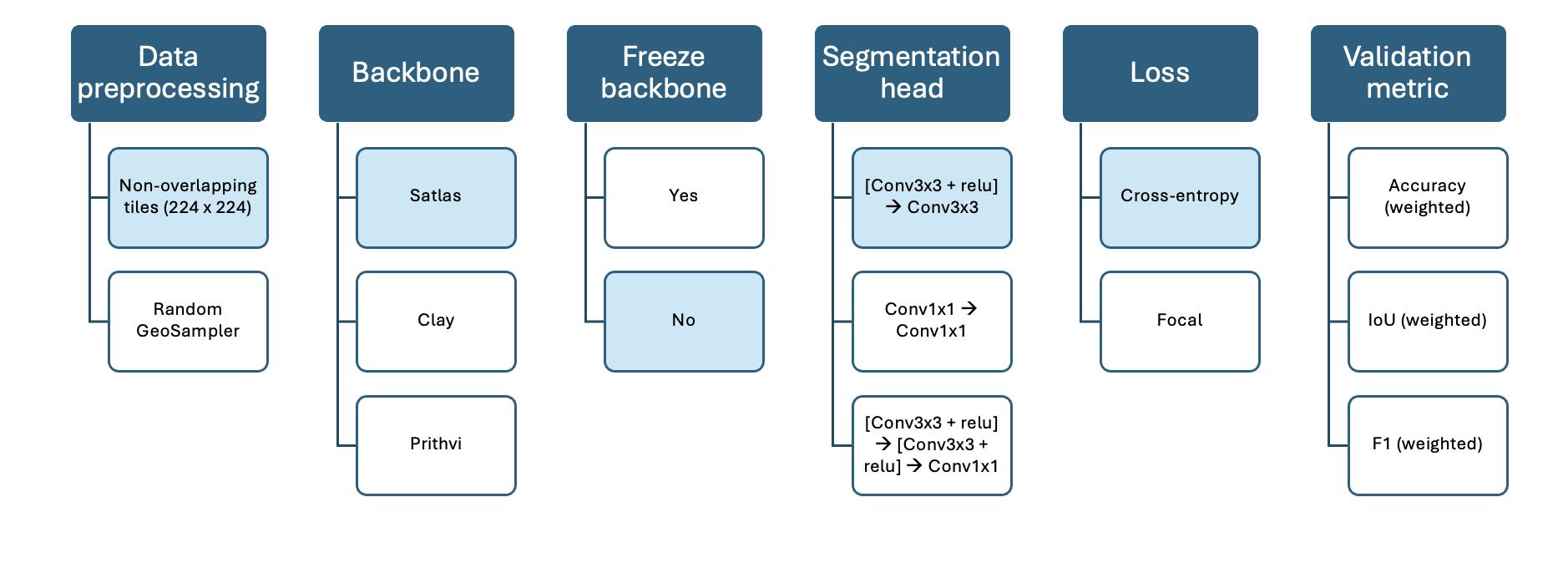
Model B: Clay
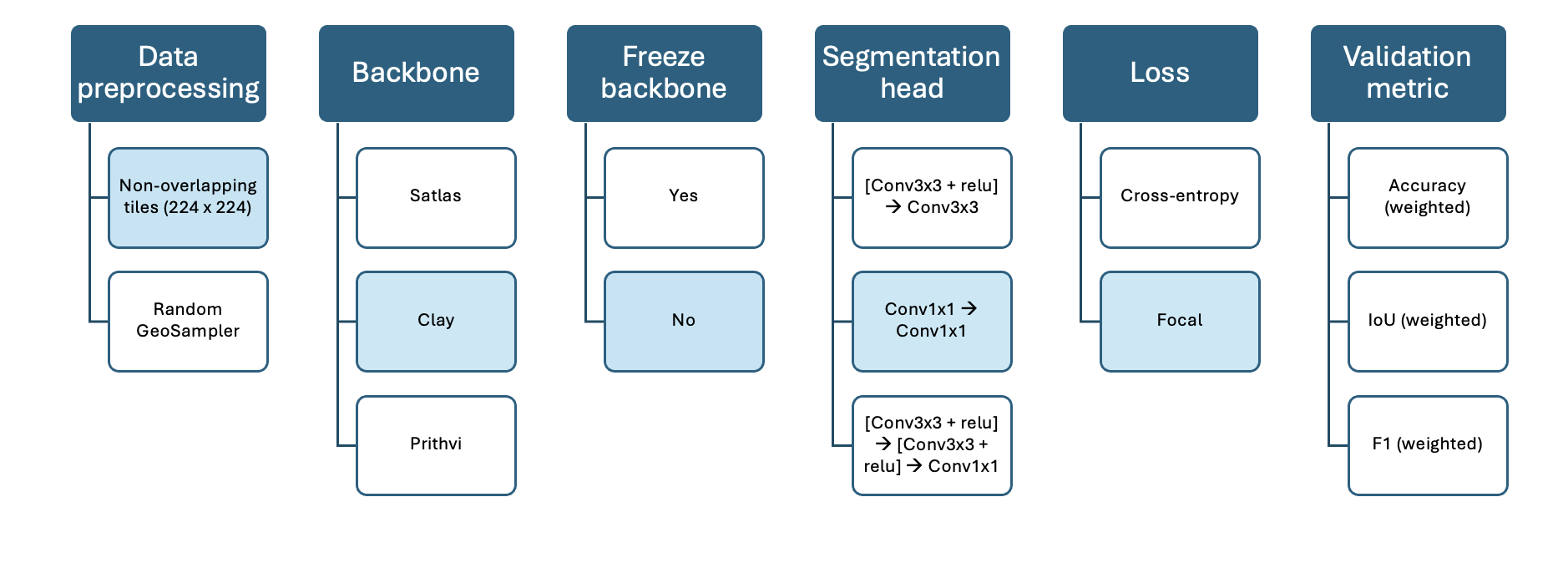
Model C: Prithvi
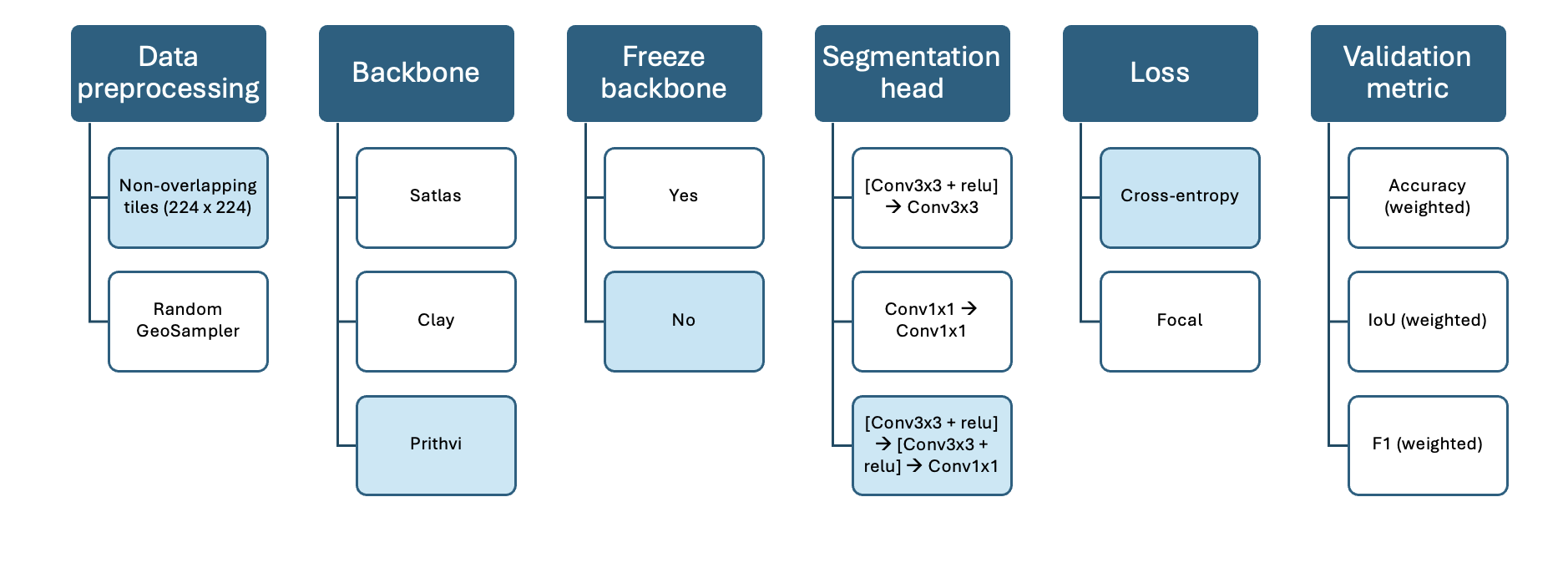
Prithvi: CE vs focal loss

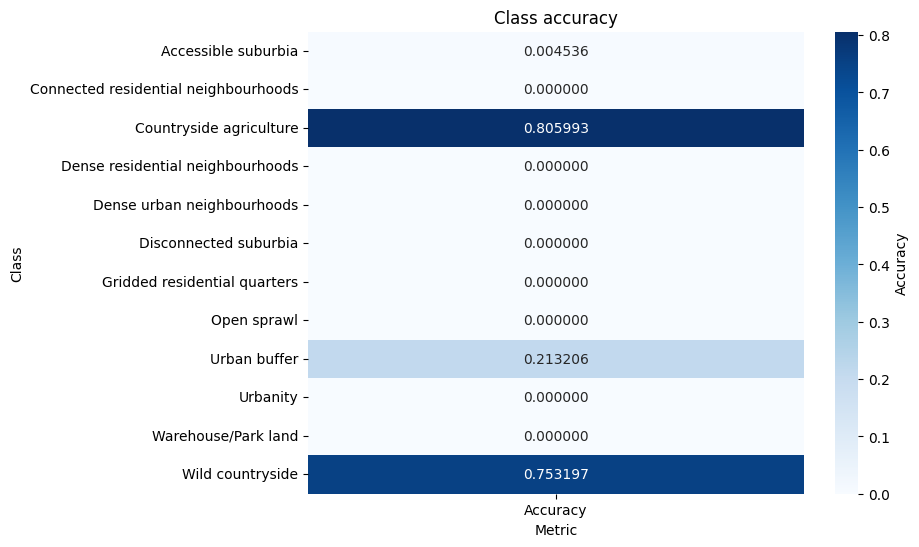
Clay predictions